
Meituan представила LongCat-2.0 — открытую MoE-модель на 1,6 трлн параметров и примерно 48 млрд активных параметров на токен. Она рассчитана на длинный контекст, работу с кодом, репозиториями и многошаговыми задачами.
LongCat-2.0 уже доступна через API-платформу LongCat. Также модель можно использовать через GitHub, Hugging Face и OpenRouter. Подробности в материале Postium.
Читайте также: Как скачать и установить Codex на ПК
Нейросеть LongCat-2.0: что умеет и как работает
LongCat-2.0 построена на MoE-архитектуре: внутри работает множество экспертных блоков, но при генерации каждого токена активируется только часть параметров. Общий размер модели — 1,6 трлн параметров, активная часть — около 48 млрд. Это снижает вычислительные затраты по сравнению с запуском всей модели целиком.
Модель обучали для работы с длинным контекстом. LongCat заявляет контекстное окно до 1 млн токенов и обучение на сотнях миллиардов токенов такой длины. Это нужно для сценариев, где модель анализирует не один запрос, а целый репозиторий, документацию, исследование или набор рабочих файлов.
Для работы с длинным контекстом в LongCat-2.0 добавили механизм LongCat Sparse Attention. Вместо обработки всего окна с одинаковыми затратами модель через индексатор выделяет наиболее важные части входных данных. Внутри используются алгоритмы streaming-aware indexing, cross-layer indexing и hierarchical indexing. Проще говоря, модель быстрее находит нужные фрагменты длинного текста и повторно использует часть вычислений между слоями.
Ещё одно изменение — N-gram Embedding. Этот модуль расширяет пространство эмбеддингов примерно в 100 раз за счёт комбинаций токенов. В LongCat-2.0 на него приходится 135 млрд параметров. Это помогает модели лучше удерживать локальные связи в тексте и коде.
Главный фокус LongCat-2.0 — разработка с ИИ-агентами. Модель можно использовать в Claude Code, OpenClaw и Hermes, где она читает файлы, вызывает инструменты, изменяет код и ведёт задачу в несколько шагов. Например, по текстовому запросу она может создать веб-приложение: спроектировать архитектуру, написать игровую логику и подготовить интерфейс.
Кроме кода, LongCat-2.0 рассчитана на анализ данных, исследовательские задачи с ИИ-агентами, подготовку баз знаний, создание презентаций и работу с длинными текстами. В таких сценариях модель получает запрос на естественном языке, планирует последовательность действий, ищет или структурирует материалы и возвращает результат.
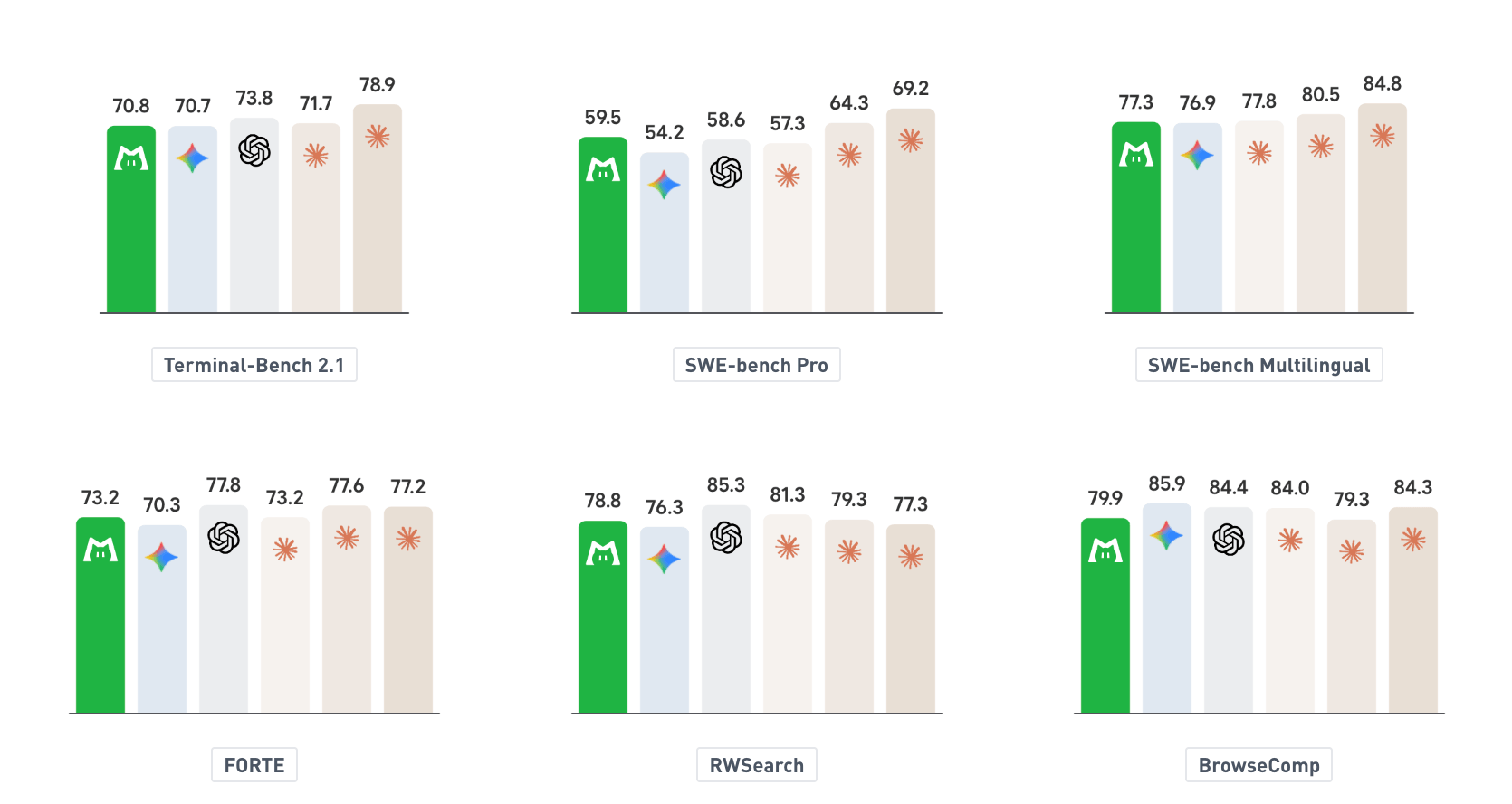
На бенчмарках LongCat заявляет 70.8 на Terminal-Bench 2.1, 59.5 на SWE-bench Pro, 77.3 на SWE-bench Multilingual, 73.2 на FORTE, 78.8 на RWSearch и 79.9 на BrowseComp.
Как пользоваться
Для работы через API нужно зайти на платформу LongCat, создать API Key и подключить модель к своему приложению или агентной среде. На платформе доступны оплата по факту использования и пакеты токенов.
На старте доступны пакеты: 50 млн токенов за $1.9 и 1 млрд токенов за $59.9. Попадания в кэш не списываются из пакета. Пакеты действуют 30 дней, а неиспользованные токены можно вернуть. Если пакет закончится, система автоматически переключится на оплату по фактическому расходу.
Почему это важно? LongCat-2.0 рассчитана на тот же класс задач, где сегодня конкурируют ИИ-агенты для разработки: работа с большими репозиториями, длинной документацией, вызов инструментов, изменение файлов и проверка результата. Для разработчика важно, чтобы модель не только отвечала в чате, но и удерживала в контексте весь проект и доводила задачу до рабочего состояния.
Итог: Meituan выпустила открытую модель LongCat-2.0 для разработки и агентных сценариев. Она поддерживает контекст до 1 млн токенов, использует архитектуру MoE и рассчитана на работу с крупными репозиториями, документацией и многошаговыми задачами.















