
Компания DeepSeek показала DeepSeek-OCR — OCR-модель, созданную специально для больших языковых моделей. Вместо обычного распознавания текста она сжимает страницу в визуальные токены, чтобы LLM могла читать документы быстрее и дешевле.
На vLLM 0.8.5 модель выдаёт около 2500 токенов в секунду на GPU A100-40G. Postium собрал ключевые детали о новинке.
Читайте также: Как писать промты для DeepSeek
DeepSeek-OCR — что это и как работает
DeepSeek-OCR — новая система распознавания текста от компании DeepSeek, созданная специально для работы с большими языковыми моделями (LLM).
Главная идея — не просто превращать изображение в текст, а сжимать визуальный контекст страницы (документа, PDF) в компактный набор токенов, которые LLM потом «распаковывает» и понимает.
Как это работает:
- Страница превращается в визуальные токены. Модель анализирует изображение (скан, PDF) и кодирует его в десятки, а не тысячи токенов.
- LLM получает компактное представление. Эти токены уже содержат информацию о тексте, структуре (таблицы, списки) и формате документа.
- Распаковка и понимание. Внутри LLM эти токены преобразуются обратно в текст и структуру — без необходимости видеть каждый пиксель.
Результат — LLM понимает документ целиком, но тратит в 10–20 раз меньше контекста, чем при обычном OCR.
На бенчмарке OmniDocBench DeepSeek-OCR опережает GOT-OCR 2.0 и MinerU 2.0, используя при этом в 2–3 раза меньше визуальных токенов.
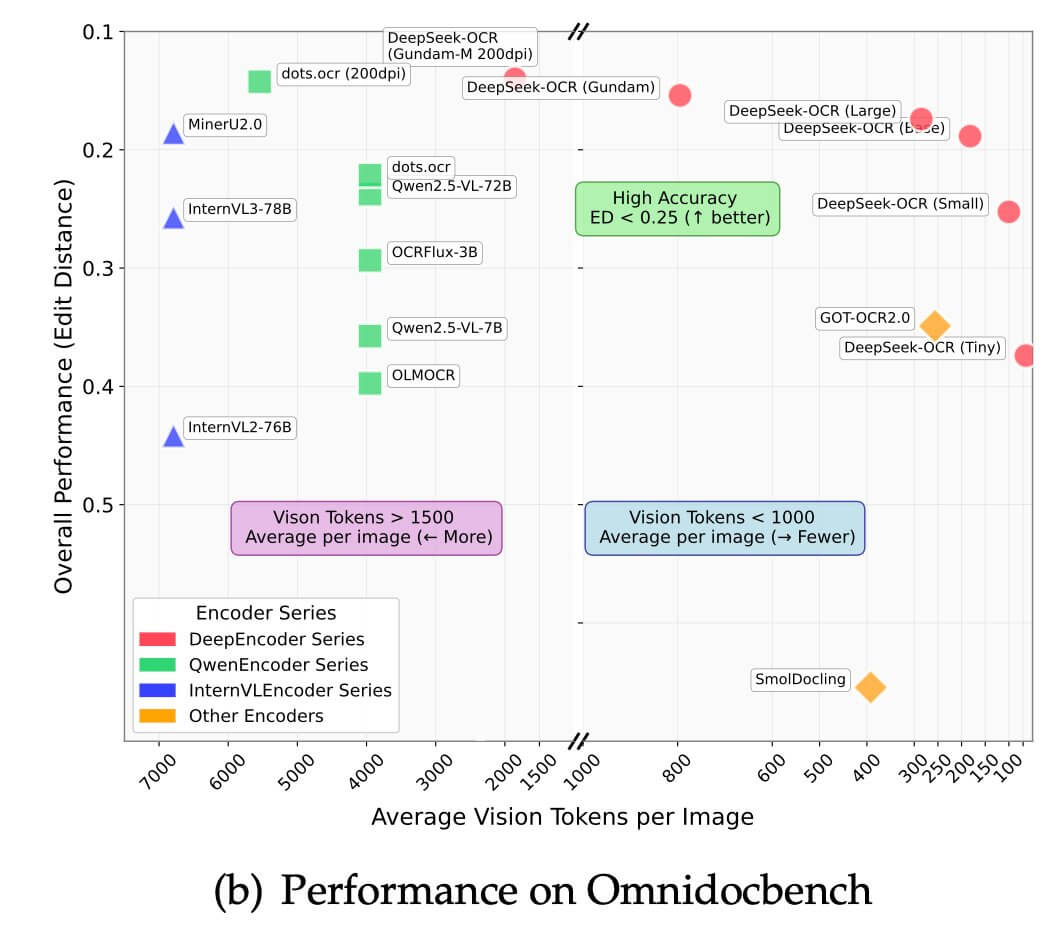
Почему это важно: DeepSeek-OCR делает работу LLM с документами быстрее — до 2500 токенов/с на GPU A100, дешевле — за счёт меньшего числа токенов при инференсе, точнее — сохраняя 97% точности при 10-кратном сжатии, и гибче — поддерживая PDF, сканы и изображения напрямую через vLLM.
Где может применяться:
- Автоматический разбор контрактов, отчётов, форм;
- Быстрое извлечение данных из длинных PDF;
- Подготовка структурированных ответов (JSON, Markdown, таблицы);
- Встраивание в RAG-пайплайны и чат-ботов с документами.
Как пользоваться? DeepSeek-OCR — инструмент для разработчиков, а не конечных пользователей. Модель можно скачать с Hugging Face или GitHub и встроить в свои пайплайны — например, в веб-сервисы, системы анализа документов или обработку больших данных.
Она принимает на вход изображения, сканы и PDF-страницы, возвращая компактные визуальные токены или распознанный текст. Совместима с vLLM 0.8.5, Transformers, PyTorch 2.6+ и работает на CUDA 11.8+.
Итог: DeepSeek-OCR не делает ИИ «зрячим» в человеческом смысле, но приближает его к тому, как человек воспринимает документ.
Раньше OCR видел только буквы и строки, не понимая, где таблица, где подпись, а где заголовок. Теперь модель передаёт LLM сжатое, но осмысленное представление страницы — так, как человек видит её целиком: и текст, и структуру, и логику оформления.
Также, недавно стало известно, что DeepSeek V4 может выйти в октябре.













